
I don’t know what it is at the moment but everybody seemingly wants to do something with XML data at the moment, it must be something in the water. This seems odd to me because nowadays XML has largely been superseded as a transport medium by JSON which is much less verbose and therefore far more frugal with regards to disk space and of course speed over the wire… but as I say,
I see trends dem man want XML
If you understand that reference you’re either heavily into Stormzy or you spend wayyyy too much time on Twitter, I’ll let you draw your own conclusions as to which camp I fall into…..
I must admit that bringing in data from XML is not something that I have really gone into much at all, at least not in this facet of my job; Back in the day we used to have a share trading application that made heavy use of XML files and schemas but that was a whole lifetime ago seemingly. When it comes to SSIS and Data Services I’ve deftly avoided this medium. It is thus no surprise that I had not encountered the XML Pipeline component. The basic premise of this component is that using a schema document it will allow you to load LARGE data from large xml documents into your database without bricking your server for the rest of time. Try bringing a massive file using only the query component and you’ll see this. The reason for this is simple, the query component attached directly to an XML source will load the entire file in order to maybe obtain just 2 or three columns. Now if you have a 6gb file thats going to get old very quickly. The XML Pipeline skirts around this issue by using an XML interrogative language developed by W3C called XPath to get ONLY the relevant data, this operation is orders of magnitudes quicker as you are not chewing up vast amounts of actual and paging memory to arrive at an answer.
Enough with the background, Lets try and bring some of this data in. For this sample I have generated 2 simple XML files and an associated schema document.
- XMLBigData.xml is the main file that contains masses of data, because of the size I do not use this for set up purposes as it could slow proceedings down
- XMLBigData_Sample.xml is a tiny subset of the main file which allows us to keep things snappy for development purposes
- XMLBigData.xsd is the schema file which I generated (using Microsoft Visual Studio, the community edition of which is free).
I cannot recommend strongly enough that you DO NOT use one of the hundreds of online sites for creating a schema based upon your data. At best its completely pointless (if you obfuscate the data) and at worst you are throwing real data at a site that could capture potentially sensitive data.
Lets take a look at our first cut of these files:-
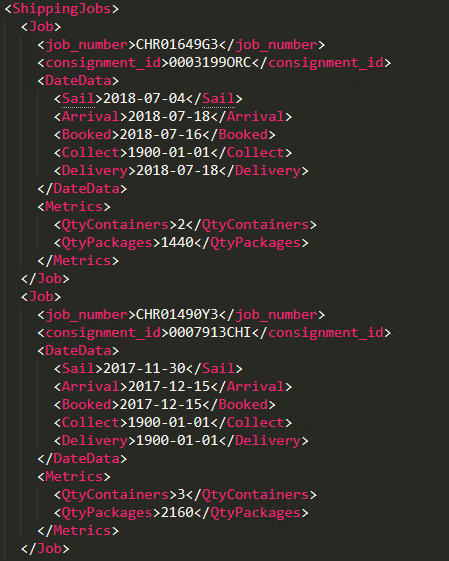
Nice and simple, so we get started by first of all creating our format by right clicking on the Nested Schemas and selecting the ‘XML Schema’ item. We then give the format a name (thank you Father Ted) and point the format at our XML Schema file that describes our XML files. Finally select the root element and we are truly ready to go so press OK.
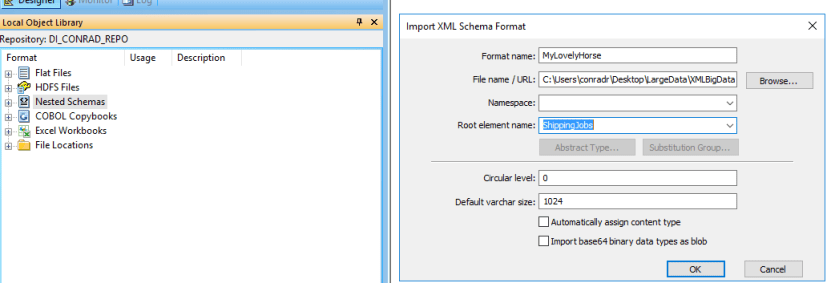
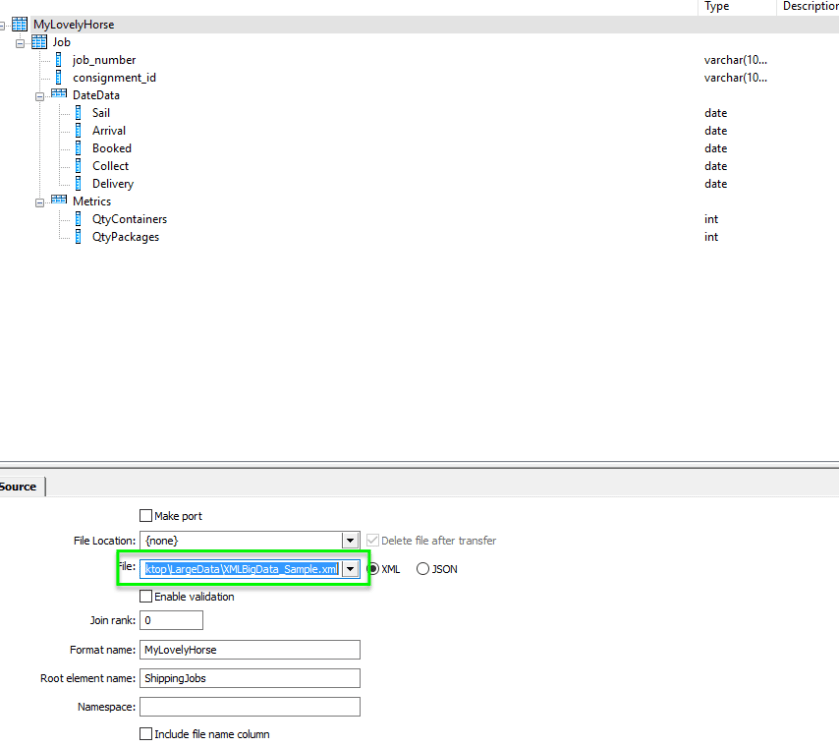
I then create the following workflow on my data flow canvas, dragging my newly created format (as a source) followed by an XML Pipeline component from the Transform tab and finally a Template table

OK, Lets set about making sure our XML Source knows where the data actually is, this we do by entering the path to our slimmer XMLBigData_Sample.xml file, everything else should be defaulted to the corrected values
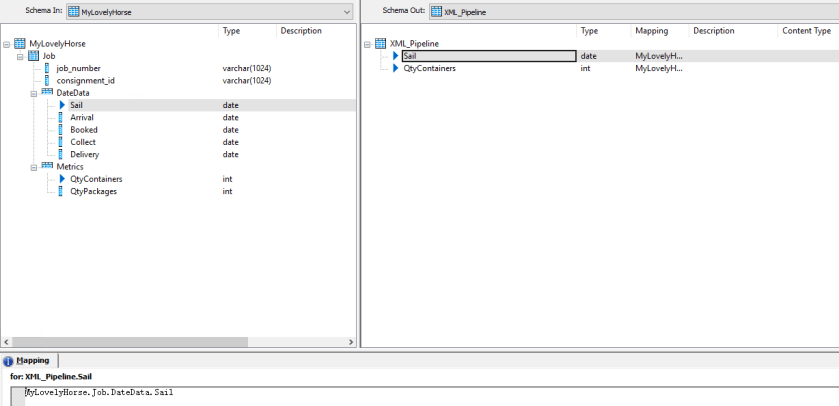
And now lets set about configuring the XML Pipeline, in this instance I am only interested in getting the Sail Dates and the QtyContainer metric values. I quite simply drag them across as the following screenshot shows
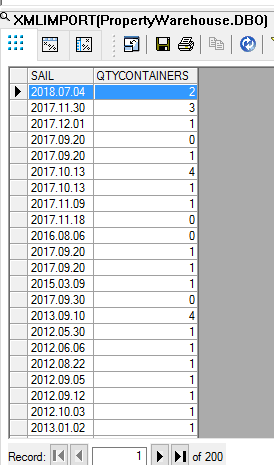
I can now try running my job, which as you can see from the following screenshot is a resounding success.
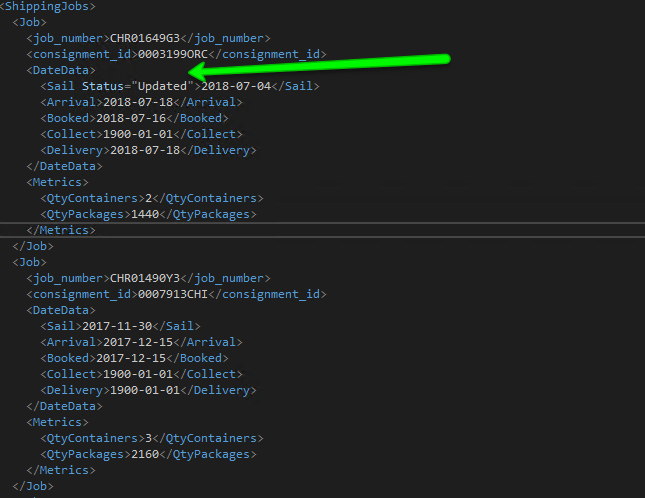
That was nice and simple. Job done right? Well if your XML is really that simple then potentially yes. However, what if you didn’t just have Node values as we have in this file… what if you had attribute values as well as we can see in a new generation of the file that I have tweaked by hand? In this case I have hand crafted the file and added a Status attribute to one (but not all) Sail Nodes.
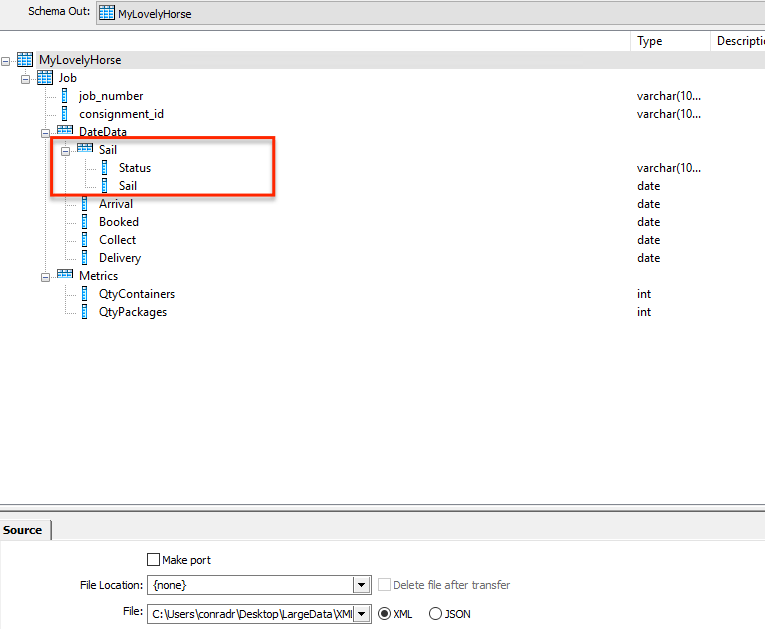
In order to describe this revised XML output I thus need to regenerate the XSD schema which should now show that the status attribute is an optional attribute against the Sail node. Once we have the schema document then this needs to be re-imported into our ‘MyLovelyHorse’ Nested Schema and once you have done this you should see that your format now looks like this, the areas that have changed marked in red.
Within our XML Pipeline we need to redefine Sail data output which now actually has a different path as you can see from the following capture, the addition ‘Sail’ in the path is in this instance telling the XML Parser to use the Value of the node. Just as an aside, this ‘little feature’ explains why you cannot import XML documents where a parent and child node have the same name. I found this out the hard way…
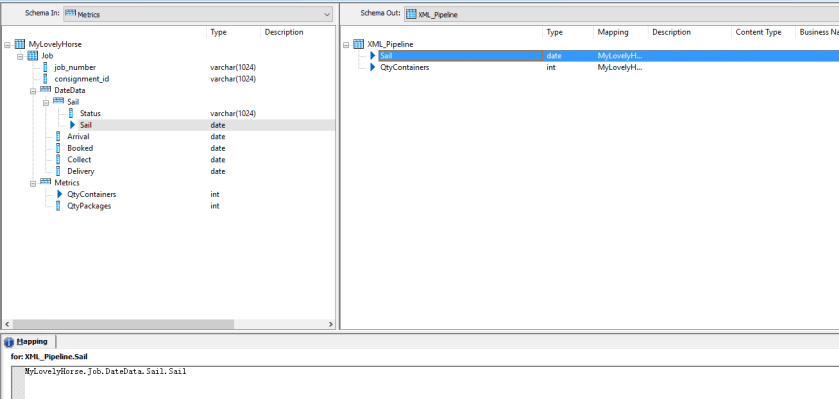
If you now run the data flow once more you will see that the data is still output, exactly as expected. Lets mix things up a little, Maybe lets try and import an attribute value as well right? Simple, we just drag that attribute into our XML Pipeline output screen as shown below.
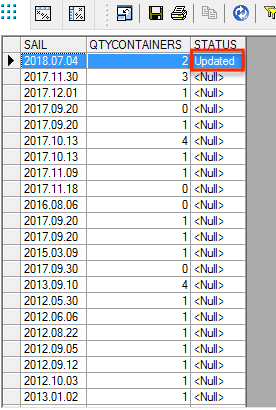
We then run the job as before and as you can see we will now see our new status column which was the attribute value. Because it is an optional item and we only have row of data with that attribute applied we only get one row output with a value in the Status column, the rest are marked as being null
That really is it….
Stuck? Read on….
Except, maybe it isn’t for you. There may be a few of you out there who are exclaiming and decrying that this does not work for you. Indeed, this was what got me interested in this particular are of functionality. We had a client contact us via our helpdesk unable to bring their own XML data in; Upon loading it I could see that they seemed to be doing nothing wrong. So I dug a little and nearly gave up but then I had a flash of inspiration which allowed me to get things working for them too. Now I’m not sure whether it was the complexity of their document, the depth of the tree, a reserved word being used in the path or that famous wind in Siberia that was to blame. I do know that we only started to see the issues when we started bringing attributes in though.
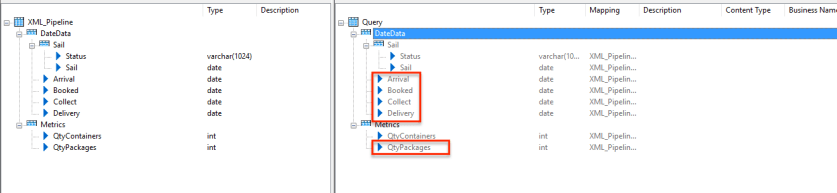
TO correct their issues I had to approach the issue slightly differently, firstly I needed to add a new Query component into our data flow so that we get the following kind of thing:-
Going back to our XML Pipeline I changed things a little, I now bring in the full node that I am interested in obtaining data from, in this instance the DateData node and the Metrics Node, theoretically I could have just bought in the Sail node in fact….
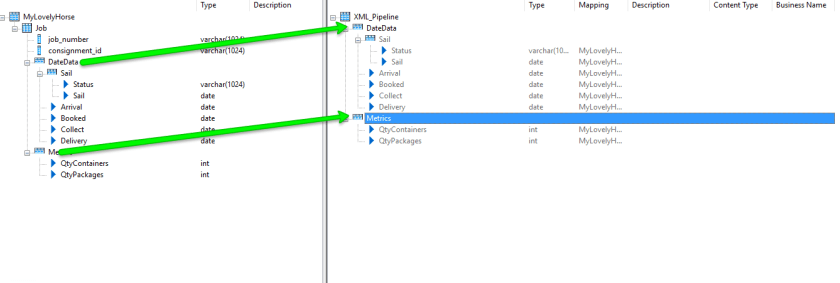
I need to do nothing else with the XML Pipeline component now, instead i sue the Query component to shape my data.. So firstly I removed the highlighted items, to do this you have to double click on an node thus making the parent node active; You can then right click and select ‘Delete’ from the popup menu.
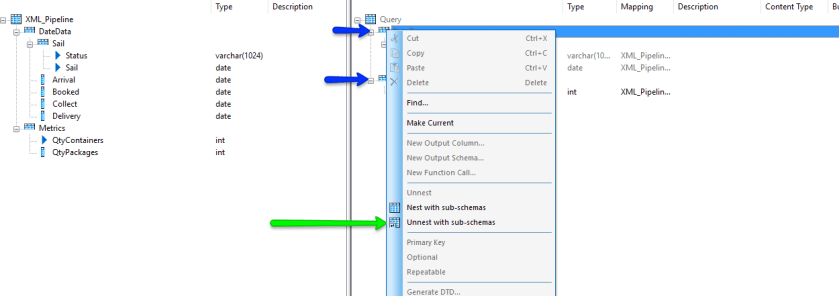
We then need to flatten our schema as what we currently have is a nested schema which is not supported for output to database targets. So we in turn select the nodes indicated by the blue arrows and then elect to Unnest with sub schemas. This has the effect of flattening your file
This flattened status is indicated by the tiny arrows underneath each of the Schema objects that have child elements.
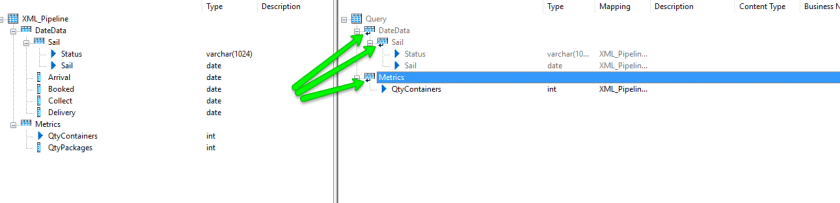
And that, really is it. If you then run this data flow you should see that your data will now appear despite it’s reticence to do so previously.
