
As I discussed in a related blog recently it is important to provide dedicated repositories within SAP Data Integrator to allow for a frictionless coexistence between Development, QA and Production. Its a paradigm shared between ETL and ‘proper’ development and after over twenty years in the software industry I don’t know a single positive story that came out of not having a firmly laid down, separated and well understood release and promotion policy. Typically with simple small web applications there will be 3 separate environments:-
The development environment which generally consists of one central source control repository for the code, many client developers each potentially with their own decentralised repository of code changes and then either one central or many satellite application databases. Added to this there may be many coding sprints occurring at once. You can see how left to its own devices this will never be a frictionless process with that many complexities involved.
The QA Environment tends to be more orderly, there may be one or many test environments (where we have multiple sprints). There will be no source controller with regard to the code itself though if there are automated tests these may well be in a source code repository. There is likely to be only one database and one web installation for each branch under testing. Much cleaner Im sure you’ll agree.
And then we get to the production environment for which there will be only one, or a few installations. The data we would expect to be kept clean and free of developers and testers. There will be no source control at this level; just backs ups of the executable and database environments.
To orchestrate and stage releases and promotions between these three quite separate environments we would typically use continuous integration mechanisms to migrate databases, web environments and the build process when required.
I’ve had a little think about what challenges there are and the benefits to be had for managing the workflows within the SAP Data Services environment. I have also read best practice documents and the one thing we can all agree on is that nobody can agree on anything. With that in mind I think it is probably best to take things on a case by case basis.
Lets start by looking at the possible configurations. It is worth pointing out from the outset that central repositories cannot execute jobs, I mean…. at all, and this is a good thing.
What is not really in doubt is that you should have one standard repository per interactive user, that is to say that each developer should certainly have a repository in which to develop and test code. It then follows that if central repositories cannot execute transformations then each member of the QA team should also have a repository in which they can execute jobs for the test cycle. Finally these jobs will then migrate to the production environment and so we should have a production repository which can take care of running the live business processes.
We then need to start thinking about how code migrates from the development cycle to the test cycle and thence onto production, the obvious answer is of course ‘Central Repositories’ which is a cross between a standard repository and a source control system. How many central repositories is the hotly contested point in all of this.
- Single Repository Model
- Two Repository Model
- Three Repository Model
Let me start out by saying that I just cannot see the point of a three repository model, The development repository would contain all of the source with releases marked using a label. QA would then download the required code into their local repository and test to their little hearts content, being QA they will not make changes to the code themselves so it follows that the only reason they would ever upload to the QA central repository is when the job is cleared for promotion to production. Thus the QA central repository would contain all of the candidate releases.
All good so far, so then the Production user would then download the latest candidate release to the production local repository ready for execution. What then would be the point of uploading this codebase once more to the production repository? Its both a dead end and in fact a complete duplicate of the QA repository.
For me the best option is the two repository system as it utilises a true promotion methodology, Production users cannot see development code and so cannot accidentally deploy it. In addition changes made by development cannot suddenly appear in what was thought to be production code and everything that ‘appears’ in the QA repository has been rigorously tested. The picture below details how a two repository deployment model would work.
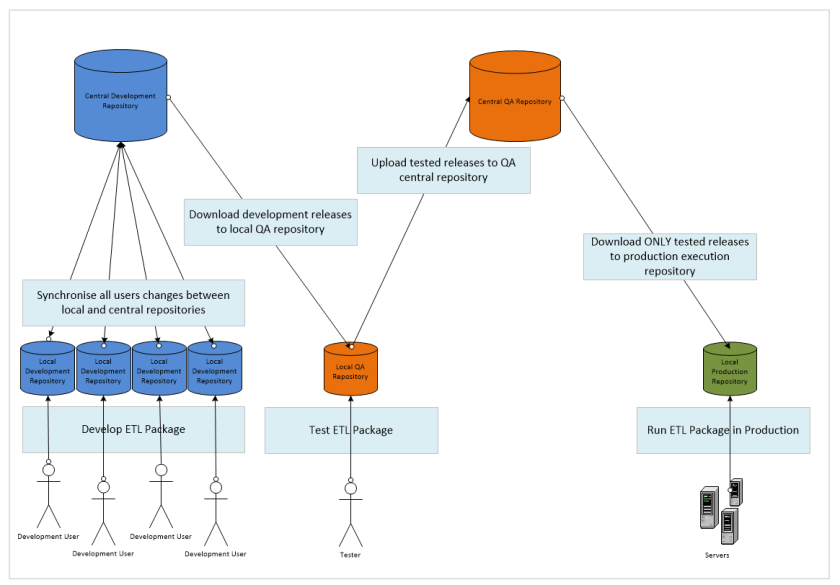
In part 2 we will look at how we would start to create and configure a central repository, I’m going to take it for granted that you have already set up local repositories.

3 comments
Comments are closed.