
I have recently been working on a third tranche of ETL work for a client which is basically a reasonably complex data warehouse. Its been a great project and I’ve loved getting down and dirty with their data although there have been some frustrating elements to the project, which as I have not worked on such a complex linear project before, I did not foresee as being an issue. This blog is a discussion of the main issue to which I will attempt to give a working strategy that can be used in preference.
To layout the issue that I encountered it is necessary to detail first what we are trying to achieve. We have a a large application database that it being constantly updated daily by a large number of systems and processes. Overnight we extract any data that has changed and apply/add these changes to the data warehouse for reporting purposes. We are only interested in the raw data, not the identifying keys within the source database as we will create our own keys within the data warehouse. We then import all of this data into a staging table from where we then sieve the data and create one fact table with foreign key relationships linking it to many many dimensional data tables. So far, uncontroversial…
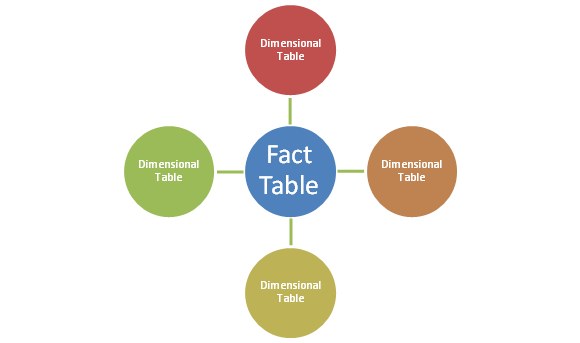
Where the difficulties arise, is exactly how you implement this and moreover how much data we are talking about. Traditionally I would take this approach to a simple migration:-
- Import Source Data into Staging Area
- Create all missing Dimensional Data (from staging data columns)
- Create Fact Table, mapping in Dimensional Foreign Keys using look up components as I go. See pic below.
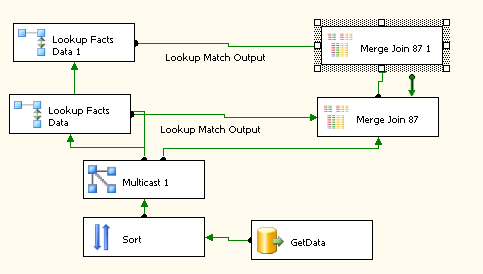
Step 3 is the issue here; in a small or medium solution it works without issue but when you start getting north of 50 dimension fields in a fact table DTS becomes very unresponsive, especially when loading/saving the ‘Merge Join’ transformation. In my instance I have about 100 of these dimensions and its starting to creak badly. Not to mention… If you need to make changes to a field in the source, you find that you have to propagate this meta data down through every single merge join component by opening it (it will inform you that it is incorrect and ask if you would like to fix the issues to which you say yes) which is time consuming! At least you do NOT need to save each merge which is a godsend as with save times of about a minute and a half for each component theres 3 hours out of your day for no good reason.
So how do you get around this issue, well alarmingly simply really although I have yet to prove this in the wild… The root of the problem is using a merge component to keep the data together (which is necessary as we’re loading from one table and saving to another in my instance). What we need to do is eliminate this costly merge and the way we do that is by resolving the foreign key fields in the staging data table, before just doing a wholesale dump of the data into the facts table. The workflow will be thus:-
- Load all of the staging data using one sql statement (as we did previously).
- Split the data as we did previously using a Multicast (one for each column that we are updating)
- Lookup each column using a lookup component (as we did previously)
- Update the ForeignKey field for the column we are looking up within the StagingTable using an OLEDB command.
- Use a straight data dump to move the data from the Staging Table to the Facts table applying any filters that you would normally have done
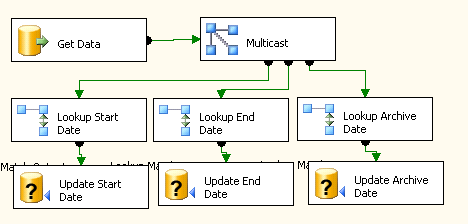
Where the warehouse is large this should make the whole edition and refactor process for a given job 100 times more pleasurable and performant than before . Sadly it is a little bit late in this iteration for me to refactor my DTS package to work like this but I will certainly be adopting this methodology in the future for all DTS work as the improvements in productivity are immeasurable, I also think that the setup costs are a lot less too as you you not need to worry about synchronising the name of the output column with its real name in the Lookup component.
As I said, I have yet to test this in anger but hopefully it will act as a heads up for anybody embarking on such an enterprise.
