
What did I ever do without the TSQL Row_Number() functionality. I do remember way back in days of yore (when I had youth, less weight and even less sleep) wishing that with straight SQL I could achieve a row count within my data. I seem to remember we cobbled something together but it was less than satisfactory. Code it seems is always about compromise…
Just recently I have been set some work that involved grouping and sorting and in addition I needed to be able to make the SQL code seemingly intelligent about where we were within the data. What we had was an Intake amount that could apply to ‘n’ records that were being detailed. We were ordering the data in such a way that only the first record should really output the Total Intake amount (as this applied to several underlying rows also). It was not helpful to look at 3 rows where the total Intake appeared to be 100 for each where in fact it was 100 for the 3 rows. To state the problem I started with a database structured thus:- 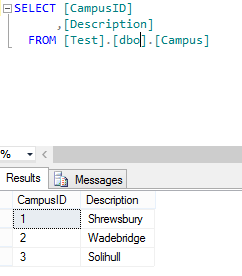 The campuses are all of the campuses where a student could attend a course. Next we had the course themselves (This is just a sample so the data is not normalised! Excuse my Faux Pas….)
The campuses are all of the campuses where a student could attend a course. Next we had the course themselves (This is just a sample so the data is not normalised! Excuse my Faux Pas….) 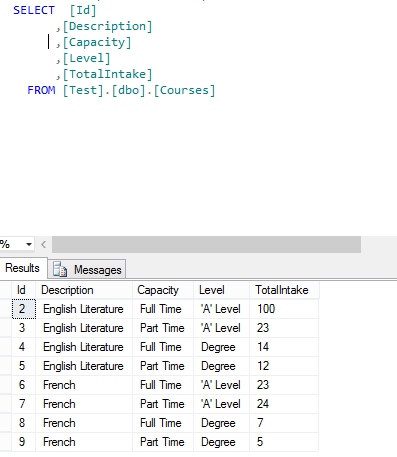 And finally the mapping table that brings this data all together…
And finally the mapping table that brings this data all together… 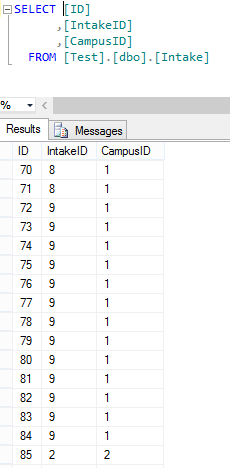 So to start with I began with a simple SQL select to join all of this data together sensibly returning only the data that a human (if we only could find one) wanted to see. As you can see, nothing onerous here:-
So to start with I began with a simple SQL select to join all of this data together sensibly returning only the data that a human (if we only could find one) wanted to see. As you can see, nothing onerous here:- 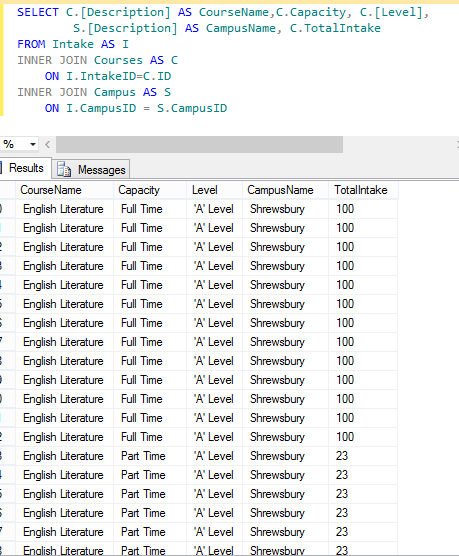 As you can see for each student we are bringing back their course, level and capacity on a 1 to 1 basis. Not very useful as what I would actually like to see is all of the courses and a count of the students underlying it So we change things around a little grouping on the Course,Level and Capacity (as well as campus) and then taking the DISTINCT (Max from a summary point of view) TotalIntake figures and applying a count of the underlying students giving us this:-
As you can see for each student we are bringing back their course, level and capacity on a 1 to 1 basis. Not very useful as what I would actually like to see is all of the courses and a count of the students underlying it So we change things around a little grouping on the Course,Level and Capacity (as well as campus) and then taking the DISTINCT (Max from a summary point of view) TotalIntake figures and applying a count of the underlying students giving us this:- 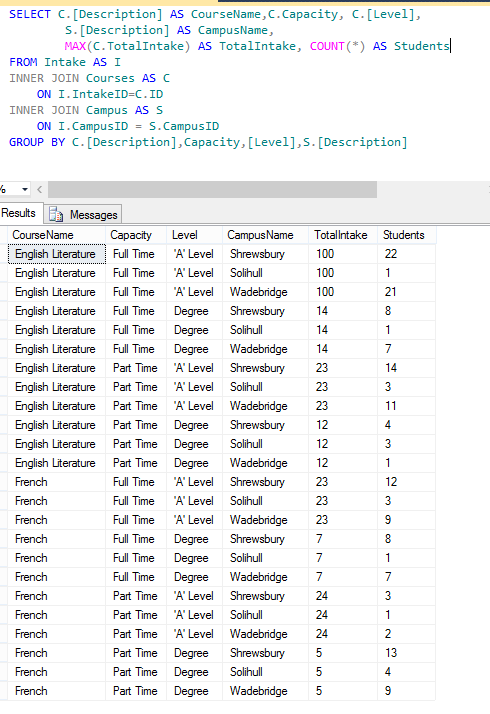 Now we’re cooking, were starting to see the data that I wanted, however if I was to scan read the above data from the first three lines presented I might think that for an intake of 300 students we had an uptake of only 44. The truth is that the 3 x 100 intake is actually 1 intake record split across the three campus…. so what I’d like to do is show the Intake only once. This means that I will have to of course order the results so that intakes are all together but we’ve already done that. So without further ado, welcome to the magic that is PARTITION. I refactored the SQL to read thus:-
Now we’re cooking, were starting to see the data that I wanted, however if I was to scan read the above data from the first three lines presented I might think that for an intake of 300 students we had an uptake of only 44. The truth is that the 3 x 100 intake is actually 1 intake record split across the three campus…. so what I’d like to do is show the Intake only once. This means that I will have to of course order the results so that intakes are all together but we’ve already done that. So without further ado, welcome to the magic that is PARTITION. I refactored the SQL to read thus:- 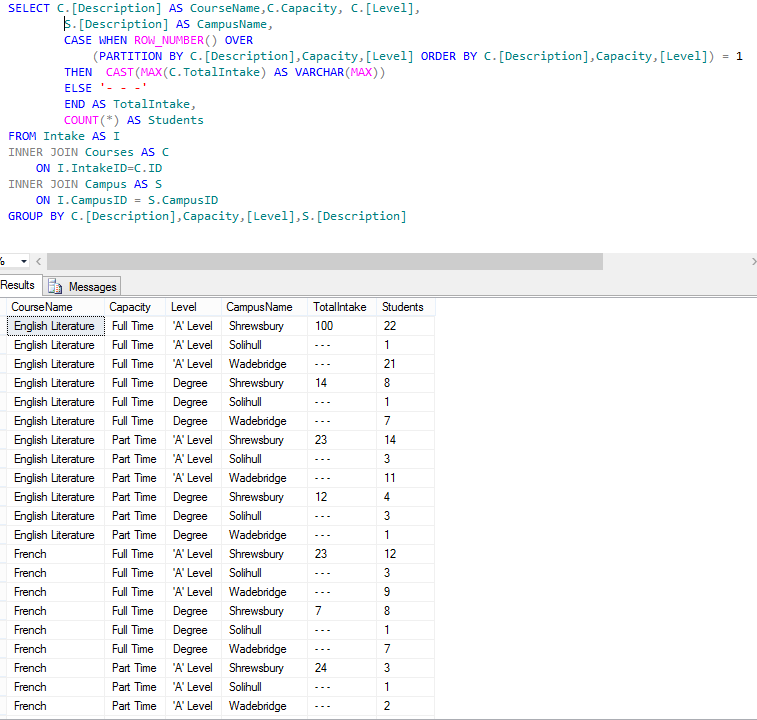 This now looks a lot better, as you can see it is now very evident that my total intake for the first three records is 100. So just to explain what is happening:- the PARTITION statement is forming a partition within the data so that whenever a new group is determined for such time as that group is in use a row number count is incremented (starting at zero for each group). In the above instance records 1,2 and 3 and would have the row numbers 1. 2 and 3 respectively as they are all English Literature, Full Time and at A Level, what sets them apart is that they are each on a different campus. We thus, using this row number, elect to output the TotalIntake only for the first record in a group. As you can see, we’re nearly there, just one thing that grates me a little. I am more interested in the records with greater amounts of students so I’d like to order them within the partition such that the campuses with the most students are reported upon first. For this we alter the ORDER BY within the partition itself:-
This now looks a lot better, as you can see it is now very evident that my total intake for the first three records is 100. So just to explain what is happening:- the PARTITION statement is forming a partition within the data so that whenever a new group is determined for such time as that group is in use a row number count is incremented (starting at zero for each group). In the above instance records 1,2 and 3 and would have the row numbers 1. 2 and 3 respectively as they are all English Literature, Full Time and at A Level, what sets them apart is that they are each on a different campus. We thus, using this row number, elect to output the TotalIntake only for the first record in a group. As you can see, we’re nearly there, just one thing that grates me a little. I am more interested in the records with greater amounts of students so I’d like to order them within the partition such that the campuses with the most students are reported upon first. For this we alter the ORDER BY within the partition itself:- 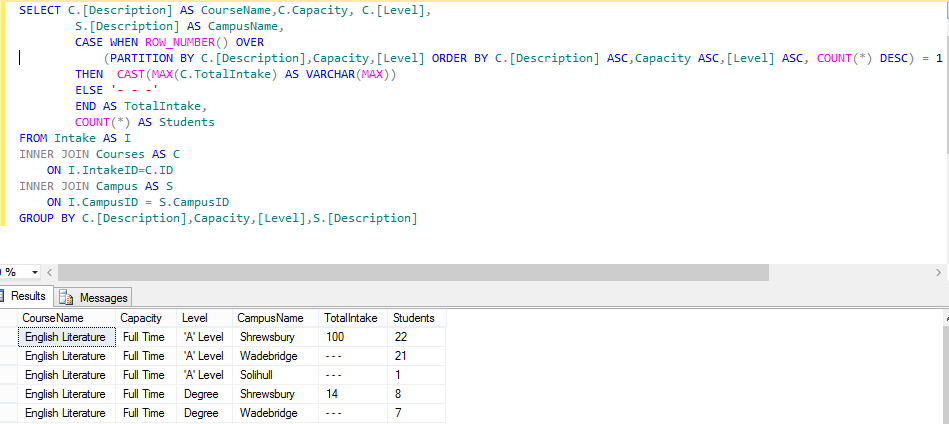 In general we need to keep the same order as the partition itself but we add a COUNT(*) DESC statement that will force the campuses with the most students to appear first (within a group). I hope you find yourself a use for this kind of location awareness within a dataset. I don’t often use it but its comforting to know that is there when you need it.
In general we need to keep the same order as the partition itself but we add a COUNT(*) DESC statement that will force the campuses with the most students to appear first (within a group). I hope you find yourself a use for this kind of location awareness within a dataset. I don’t often use it but its comforting to know that is there when you need it.
